Введение в экспертные системы
Разделение узлов в дереве гипотез...
Разделение узлов в дереве гипотез. Узлы активизированных гипотез вычерчены утолщенными прямоугольниками, а узел наиболее правдоподобной гипотезы и его дочерние узлы залиты серым цветом
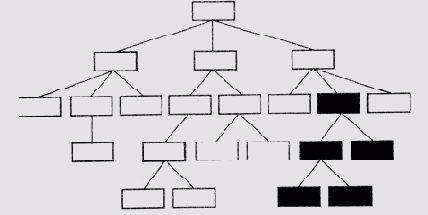
В таком разделении используется концепция доминирования, которой придается следующий смысл. Модель заболевания D1 доминирует над D2 в том случае, если наблюдаемые проявления, которые не могут быть объяснены гипотезой D1, входят как подмножество в число проявлений, которые не объясняются и гипотезой D2. Если мы выделили наиболее правдоподобную гипотезу D0 среди всех активизированных на первом этапе, то каждая из остальных гипотез Di сравнивается с гипотезой Do Если D0 доминирует над Di или Di доминирует над Do, то Di включается в ту же группу "привилегированных" гипотез, что и Do Эта группа должна рассматриваться программой в первую очередь. В противном случае Д включается в другую группу гипотез, анализ которых откладывается на будущее.
Рациональное зерно в таком разделении в том, что модели, включенные в привилегированную группу на любом этапе уточнения, можно считать взаимно исключающими альтернативами. Такое заключение основано на том, что для любых гипотез (моделей) Di и Dj в этой группе диагноз, включающий Di иDj, добавит очень немного или не добавит ничего к "полноте накрытия" каждой из гипотез Di и Dj по отдельности. На следующем этапе уточнения модели обрабатываются по той же методике, если проблема выбора среди моделей, связанных с Do, будет решена. Разделение начинается с нового узла Do, который получит наивысшую оценку среди уточняемых моделей.
Уже после ввода первой порции исходных данных будет активизирована только часть всех узлов дерева. Теперь задача программы состоит в том, чтобы преобразовать дерево из исходного состояния в состояние решения. В состоянии решения дерево должно включать только те терминальные узлы, которые в совокупности "накрывают" все имеющиеся симптомы.
Разделив модели заболеваний, программа может использовать ряд альтернативных стратегий, которые выбираются в зависимости от количества обрабатываемых гипотез.
- Если обрабатывается более четырех гипотез, используется стратегия опровержения (режим RULEOUT). Смысл ее заключается в том, чтобы как можно сильнее свернуть дерево пространства гипотез, задавая пользователю вопросы о симптомах, которые являются наиболее сильными индикаторами гипотез-кандидатов.
- Если количество анализируемых гипотез не превышает четырех, но больше одной, используется стратегия дифференциации (режим DISCRIMINATE). При этом пользователю задают вопросы, которые помогут выбрать между гипотезами-кандидатами.
- Если анализируется всего одна гипотеза, используется стратегия верификации (режим PURSUING). Пользователю задают вопросы, способные подтвердить справедливость анализируемой гипотезы.